
RuntimeError: CUDA error: an illegal memory access was encountered
爆显存?还是爆内存了?o(╥﹏╥)o……
上面还有吗?错误信息没截全。
对于这个错误,通常是显存出现了无效的访问,最有可能是代码出现了bug。
以下是日志,我估计不是爆内存就是爆显存了,我把ctx_len从4096修改成1536(以为我前面算错了),现在正常的在试跑了。
[rank0]: ^^^^^^^^^^^^^^^^^^^^^^^^^
[rank0]: RuntimeError: CUDA error: an illegal memory access was encountered
[rank0]: CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
[rank0]: For debugging consider passing CUDA_LAUNCH_BLOCKING=1
[rank0]: Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
[rank0]:[W1218 09:33:58.585653923 ProcessGroupNCCL.cpp:1250] Warning: WARNING: process group has NOT been destroyed before we destruct ProcessGroupNCCL. On normal program exit, the application should call destroy_process_group to ensure that any pending NCCL operations have finished in this process. In rare cases this process can exit before this point and block the progress of another member of the process group. This constraint has always been present, but this warning has only been added since PyTorch 2.4 (function operator())又报错了!!!估计又是爆显存?( Ĭ ^ Ĭ )
[rank0]:[E1218 11:52:45.492490493 ProcessGroupNCCL.cpp:616] [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=3588, OpType=ALLREDUCE, NumelIn=7819264, NumelOut=7819264, Timeout(ms)=600000) ran for 636800 milliseconds before timing out.
[rank0]:[E1218 11:52:45.500951070 ProcessGroupNCCL.cpp:1785] [PG ID 1 PG GUID 1 Rank 0] Exception (either an error or timeout) detected by watchdog at work: 3588, last enqueued NCCL work: 3590, last completed NCCL work: 3587.
[rank0]:[E1218 11:52:45.500982587 ProcessGroupNCCL.cpp:1834] [PG ID 1 PG GUID 1 Rank 0] Timeout at NCCL work: 3588, last enqueued NCCL work: 3590, last completed NCCL work: 3587.
[rank0]:[E1218 11:52:45.500990042 ProcessGroupNCCL.cpp:630] [Rank 0] Some NCCL operations have failed or timed out. Due to the asynchronous nature of CUDA kernels, subsequent GPU operations might run on corrupted/incomplete data.
[rank0]:[E1218 11:52:45.501004180 ProcessGroupNCCL.cpp:636] [Rank 0] To avoid data inconsistency, we are taking the entire process down.
[rank0]:[E1218 11:52:45.504485078 ProcessGroupNCCL.cpp:1595] [PG ID 1 PG GUID 1 Rank 0] Process group watchdog thread terminated with exception: [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=3588, OpType=ALLREDUCE, NumelIn=7819264, NumelOut=7819264, Timeout(ms)=600000) ran for 636800 milliseconds before timing out.
Exception raised from checkTimeout at ../torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp:618 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x96 (0x7f1fda4b9446 in /home/habby/anaconda3/lib/python3.12/site-packages/torch/lib/libc10.so)
frame #1: c10d::ProcessGroupNCCL::WorkNCCL::checkTimeout(std::optional<std::chrono::duration<long, std::ratio<1l, 1000l> > >) + 0x282 (0x7f1f8fdc8a92 in /home/habby/anaconda3/lib/python3.12/site-packages/torch/lib/libtorch_cuda.so)
frame #2: c10d::ProcessGroupNCCL::watchdogHandler() + 0x233 (0x7f1f8fdcfed3 in /home/habby/anaconda3/lib/python3.12/site-packages/torch/lib/libtorch_cuda.so)
frame #3: c10d::ProcessGroupNCCL::ncclCommWatchdog() + 0x14d (0x7f1f8fdd193d in /home/habby/anaconda3/lib/python3.12/site-packages/torch/lib/libtorch_cuda.so)
frame #4: <unknown function> + 0x145c0 (0x7f1fda8e15c0 in /home/habby/anaconda3/lib/python3.12/site-packages/torch/lib/libtorch.so)
frame #5: <unknown function> + 0x9ca94 (0x7f1fdb1fea94 in /lib/x86_64-linux-gnu/libc.so.6)
frame #6: <unknown function> + 0x129c3c (0x7f1fdb28bc3c in /lib/x86_64-linux-gnu/libc.so.6)
terminate called after throwing an instance of 'c10::DistBackendError'
what(): [PG ID 1 PG GUID 1 Rank 0] Process group watchdog thread terminated with exception: [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=3588, OpType=ALLREDUCE, NumelIn=7819264, NumelOut=7819264, Timeout(ms)=600000) ran for 636800 milliseconds before timing out.
Exception raised from checkTimeout at ../torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp:618 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x96 (0x7f1fda4b9446 in /home/habby/anaconda3/lib/python3.12/site-packages/torch/lib/libc10.so)
frame #1: c10d::ProcessGroupNCCL::WorkNCCL::checkTimeout(std::optional<std::chrono::duration<long, std::ratio<1l, 1000l> > >) + 0x282 (0x7f1f8fdc8a92 in /home/habby/anaconda3/lib/python3.12/site-packages/torch/lib/libtorch_cuda.so)
frame #2: c10d::ProcessGroupNCCL::watchdogHandler() + 0x233 (0x7f1f8fdcfed3 in /home/habby/anaconda3/lib/python3.12/site-packages/torch/lib/libtorch_cuda.so)
frame #3: c10d::ProcessGroupNCCL::ncclCommWatchdog() + 0x14d (0x7f1f8fdd193d in /home/habby/anaconda3/lib/python3.12/site-packages/torch/lib/libtorch_cuda.so)
frame #4: <unknown function> + 0x145c0 (0x7f1fda8e15c0 in /home/habby/anaconda3/lib/python3.12/site-packages/torch/lib/libtorch.so)
frame #5: <unknown function> + 0x9ca94 (0x7f1fdb1fea94 in /lib/x86_64-linux-gnu/libc.so.6)
frame #6: <unknown function> + 0x129c3c (0x7f1fdb28bc3c in /lib/x86_64-linux-gnu/libc.so.6)
Exception raised from ncclCommWatchdog at ../torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp:1601 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x96 (0x7f1fda4b9446 in /home/habby/anaconda3/lib/python3.12/site-packages/torch/lib/libc10.so)
frame #1: <unknown function> + 0xe7eb1b (0x7f1f8fa46b1b in /home/habby/anaconda3/lib/python3.12/site-packages/torch/lib/libtorch_cuda.so)
frame #2: <unknown function> + 0x145c0 (0x7f1fda8e15c0 in /home/habby/anaconda3/lib/python3.12/site-packages/torch/lib/libtorch.so)
frame #3: <unknown function> + 0x9ca94 (0x7f1fdb1fea94 in /lib/x86_64-linux-gnu/libc.so.6)
frame #4: <unknown function> + 0x129c3c (0x7f1fdb28bc3c in /lib/x86_64-linux-gnu/libc.so.6)
Aborted (core dumped)
我把日志复制到智谱清言看了下,它返回这些内容:
错误信息 “Watchdog caught collective operation timeout” 并不直接表明是显存溢出(out of memory,OOM)导致的。这个错误更多地与 NCCL 操作的超时有关,可能是因为多种原因,包括但不限于显存问题。
以下是几个可能导致 NCCL 操作超时的原因,其中包括显存相关的问题:
- 显存不足:如果您的程序在执行 NCCL 操作时耗尽了 GPU 显存,可能会导致操作失败或超时。但是,在这种情况下,通常会有更明确的 OOM 错误信息。
- 网络问题:NCCL 操作依赖于高速网络连接。如果网络带宽不足或延迟过高,可能会导致操作超时。
- GPU 计算负载过高:如果 GPU 正在执行其他重负载任务,可能会导致 NCCL 操作延迟。
- 软件配置问题:NCCL 操作的配置可能不正确,例如超时设置过短。
- 硬件故障:GPU 或网络硬件的故障也可能导致 NCCL 操作失败。
要确定是否是显存问题,您可以:
- 监控显存使用情况:使用工具如
nvidia-smi实时监控 GPU 显存的使用情况。 - 检查错误日志:查看是否有显存相关的错误信息,如 “CUDA out of memory”。
- 增加显存检查:在代码中添加显存检查的语句,以确保在执行 NCCL 操作之前有足够的显存。
如果监控显示显存使用率接近或达到 GPU 的最大容量,那么显存不足可能是导致 NCCL 操作超时的原因之一。在这种情况下,您可能需要优化代码以减少显存使用,或者考虑使用具有更多显存的 GPU。
(所以,果然是爆显存了吧!o(╥﹏╥)o)
补充一下,这是完整日志:
Ubuntu Pastebin
把你的sh发出,这个应该是有bug
以下是bone的.sh文件,另外……我确认了一下我的各种库的版本:
Python 3.12.8
Torch 2.5.1+cpu
Driver Version: 566.14
CUDA Version: 12.7
(……怪不得练得那么慢……+cpu的torch???)
load_model='/mnt/f/AI_software/RWKV-Runner/models/RWKV-x060-World-7B-v3-20241112-ctx4096.pth'
proj_dir='/mnt/f/output_lora'
data_file='/mnt/f/json2binidx_tool-main/data/0.merged_output_text_document'
n_layer=32
n_embd=4096
micro_bsz=4
epoch_save=5
epoch_steps=1000
ctx_len=1536
bone_config='{"bone_mode":"bone","bone_load":"","bone_r":64}'
python train.py --load_model $load_model \
--proj_dir $proj_dir --data_file $data_file \
--vocab_size 65536 \
--n_layer $n_layer --n_embd $n_embd \
--data_type binidx --dataload pad --loss_mask pad \
--ctx_len $ctx_len --micro_bsz $micro_bsz \
--epoch_steps $epoch_steps --epoch_count 5 --epoch_begin 0 --epoch_save $epoch_save \
--lr_init 2e-5 --lr_final 2e-5 --warmup_steps 0 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 \
--accelerator gpu --devices 1 --precision bf16 --strategy deepspeed_stage_1 --grad_cp 1 \
--my_testing "x060" \
--peft bone --bone_config $bone_config
先重启电脑,然后准备安装。
-
下载CUDA 12.4看这个:
https://developer.nvidia.com/cuda-12-4-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04&target_type=runfile_local
运行命令,中间可能会要求你暂时关闭一会儿图形界面,用sudo systemctl stop gdm3或者ctrl+alt+f2进入命令行界面。输入命令运行安装程序,安装完成后重启。 -
conda create一个新的Python 3.12运行环境:
conda create -n "名字" python=3.12
conda activate 名字 -
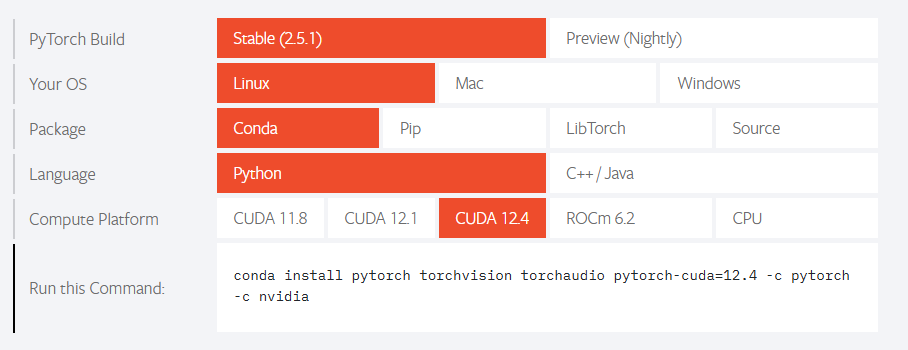
pytorch安装,运行这条命令:
-
进入RWKV-PEFT,
pip install -r requirements.txt -
开始训练!
呃,但我用的是Windows系统,用wls2才操作的诶,我全程得在wls2里安装cuda吧?

最好runfile(local),这样如果你后面的步骤不小心搞坏了,可以重装而不必重新下载。
(其实我认为直接重装pytorch换成2.5.1+cu124就可以了,但为了确保可行和避免更多的麻烦,强烈建议开一个新环境)
1 个赞
我按照你的教程先更新了pytorch,用这个语句“conda install pytorch torchvision torchaudio pytorch-cuda=12.4 -c pytorch -c nvidia”,然后现在研究cuda,打算从12.1更新到12.4。结果,我看了下我现在电脑的cuda,已经是12.4的版本了???
(base) habby@DESKTOP-TBF00LE:~$ python3
Python 3.12.8 | packaged by Anaconda, Inc. | (main, Dec 11 2024, 16:31:09) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> print(f"PyTorch version: {torch.__version__}")
PyTorch version: 2.5.1
>>> print(f"CUDA available: {torch.cuda.is_available()}")
CUDA available: True
>>> print(f"CUDA version: {torch.version.cuda}")
CUDA version: 12.4
???
所以说,这条语句是不是直接把cuda一起更新了?
另外,如果CUDA12.4是正确的配置的话,这个链接的教程得改一改了诶:
微调环境配置 - RWKV微调
没问题的话,现在就可以开始微调了。
教程本身没问题,是你原本没有正确安装带 CUDA 的 torch。话说跟着教程的步骤,你应该会安装 cu121 的 torch,所以我也不知道你中间是否更改了一些环境配置。但无论如何,能过最后的检测,证明现在已经可以训练了![]() !
!
1 个赞
原本是正确的cuda12.1,没错,但torch是+cpu的torch……不知道为什么。后面我装了2.5.1的torch嘛,cuda就自己变成12.4了。
torch 后面的 cu124 是 cuda12.4 的意思
我终于成功跑过一轮了!!!得到了两个lora!!!
epoch save= 5 意味着每隔五轮保存一个 LoRA 文件,如果你希望每一轮都保存 LoRA 以便测试,请改为 =1
1 个赞
谢谢指点,我终于炼出自己的lora啦!虽然效果,哈哈哈,我再调整调整!