运行环境
Mac m1 Pro 16 GB
Windows10
intel I7-8700
RTX 2070 8G
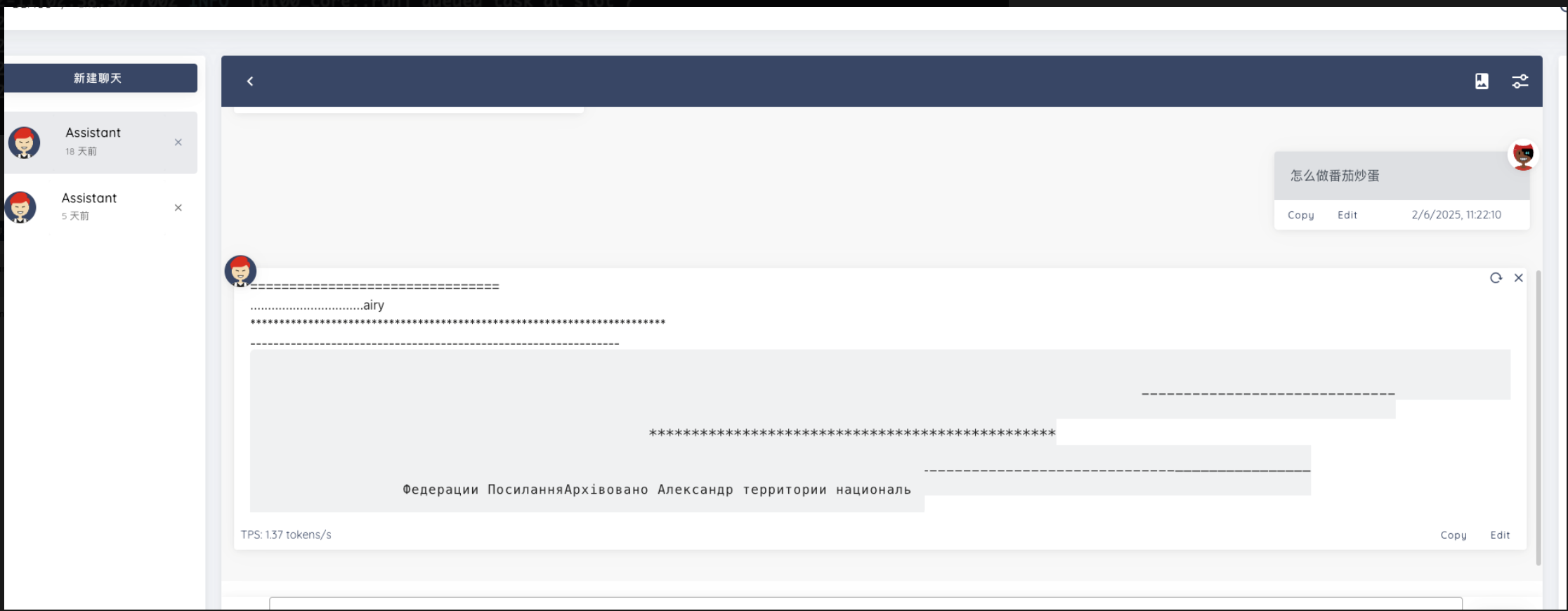
之前运行的是 3B 模型,功能正常;换成 7B 模型之后,开始输出乱码,不清楚是什么问题
请问下模型是直接下载的st模型还是自己转的?是不是用可执行文件转的?如果是的话,请用py脚本转模型到st,或者到 https://huggingface.co/cgisky/ai00_rwkv_x060/tree/main https://huggingface.co/cgisky/RWKV-x070-Ai00/tree/main/world_v3 下载转换好的模型
模型是直接从 hf 下载的 st 文件
是否尝试更新显卡驱动?此外,能否看一下你的配置文件
请问 Ai00 版本号是?
Ai00 版本为 最新的 0.5.13
config 如下
[model]
embed_device = "Cpu" # Device to put the embed tensor ("Cpu" or "Gpu").
max_batch = 8 # The maximum batches that are cached on GPU.
name = "RWKV-x060-World-7B-v3-20241112-ctx4096.st" # Name of the model.
path = "assets/models" # Path to the folder containing all models.
precision = "Fp16" # Precision for intermediate tensors ("Fp16" or "Fp32"). "Fp32" yields better outputs but slower.
quant = 0 # Layers to be quantized.
quant_type = "Int8" # Quantization type ("Int8" or "NF4").
stop = ["\n\n"] # Additional stop words in generation.
token_chunk_size = 128 # Size of token chunk that is inferred at once. For high end GPUs, this could be 64 or 128 (faster).
# [[state]] # State-tuned initial state.
# id = "fd7a60ed-7807-449f-8256-bccae3246222" # UUID for this state, which is used to specify which one to use in the APIs.
# name = "x060-3B" # Given name for this state (optional).
# path = "rwkv-x060-chn_single_round_qa-3B-20240505-ctx1024.state"
# [[state]] # Load another initial state.
# id = "6a9c60a4-0f4c-40b1-a31f-987f73e20315" # UUID for this state.
# path = "rwkv-x060-chn_single_round_qa-3B-20240502-ctx1024.state"
# [[lora]] # LoRA and blend factors.
# alpha = 192
# path = "assets/models/rwkv-x060-3b.lora"
[tokenizer]
path = "assets/tokenizer/rwkv_vocab_v20230424.json" # Path to the tokenizer.
[bnf]
enable_bytes_cache = true # Enable the cache that accelerates the expansion of certain short schemas.
start_nonterminal = "start" # The initial nonterminal of the BNF schemas.
[adapter]
Auto = {} # Choose the best GPU.
# Manual = 0 # Manually specify which GPU to use.
[listen]
acme = false
domain = "local"
ip = "0.0.0.0" # Use IpV4.
# ip = "::" # Use IpV6.
force_pass = true
port = 65530
slot = "permisionkey"
tls = false
[[listen.app_keys]] # Allow mutiple app keys.
app_id = "admin"
secret_key = "ai00_is_good"
[web] # Remove this to disable WebUI.
path = "assets/www/index.zip" # Path to the WebUI.
# [embed] # Uncomment to enable embed models (via fast-embedding onnx models).
# endpoint = "https://hf-mirror.com"
# home = "assets/models/hf"
# lib = "assets/ort/onnxruntime.dll" # Only used under windows.
# name = { MultilingualE5Small = {} }
config 见楼上,应该和显卡驱动没关系,运行 3B 模型没有问题
看起来加载的模型远大于你的显存容量,这可能是计算出错的原因。可否尝试 NF4 量化 32 层?
确实,我在 mac 上调整了配置参数使用NF4 量化 32 层,输出的内容已经可以理解了,稍后我在 Windows10 环境尝试一下