1. State tuning 简介
在Transformer主导的时代,RWKV作为一种纯RNN模型拥有固定大小的state,可以Transformer难以实现的事情。例如State tuning正是基于这一特性,通过对初始state的优化而非修改模型权重,实现轻量级而高效的模型定制。这种方法相当于"最彻底的prompt tuning",具有极强的迁移能力,甚至能通过这种状态调整实现alignment。研究表明,经过良好调优的小型RWKV模型在特定任务上可超越更大的基础模型[1][2]。
RWKV-7模型的核心是一个状态矩阵 S_t \in \mathbb{R}^{N \times N} ,其中 N=C/H,C 和 H 分别对应模型的维度和head数。状态随时间演化的规则为:
式中 t 为当前时间步, w_t,k_t, v_t, a_t 是输入文本基于预训练的权重计算而来的矢量。模型的输出为:
其中 r_t \in \mathbb{R}^N 为接受矢量,控制对过去信息的接受程度。
State tuning 的目标为特定任务初始化最优的状态矩阵。训练时,在时间步 t 下根据目标数据集的输入文本和预训练的权重计算矢量 w_t,k_t, v_t, a_t 来计算状态矩阵 S_t 的损失值,再通过交叉熵等方法优化 S_t 以最小化特定任务下的损失。这种方法计算高效,它保留了编码在预训练权重中的一般知识,同时允许通过状态矩阵进行特定于任务的自适应。
为了进一步增强模型的容量,State tuning还有一种使用核函数方法来放大状态维度大小的动态调整方法,可以使状态矩阵 S_t \in \mathbb{R}^{N \times N} 适配一个更高维的空间 \mathbb{R}^{M \times M}(M>N) 。
这种方法首先随机采样或者数据驱动选择一组支持向量 \{u_1, u_2, \cdots, u_M\} \subset \mathbb{R}^N ,然后基于高斯核函数 K(u,v) = \exp(-\gamma \Vert u-v \Vert ^2) 来实现对矢量 w_t,k_t, v_t, a_t, r_t 来调整维度,其中 \gamma 为大于0的超参数。以 w_t 为例,其对应的核特征矢量为:
于是基于核转换方法的状态演化规则和输出则为:
最后再通过一个固定的投影矩阵 Q\in \mathbb{R}^{N \times M} 来将输出恢复为原始维度:
这种核函数的方法可以进一步增强模型的表达能力。
此外 State tuning 进一步还有DBP增强tuning和测试时间缩放的方法,前者使用去相关的反向传播来加快收敛速度和更好的推理,后者通过更大的模型指导来适应推理时的状态。
2. 微调训练
本次测试基于State Tuning 微调教程,使用NekoQA-10K数据作为语料库,其中包含10066条猫娘风格的对话,并转化为RWKV标准的单轮对话数据格式的JSONL文件,如:
{"text":"User: 为什么你总是对光过敏?\n\nAssistant: (缩成黑影里的毛团)因、因为强光是魔法攻击喵!(用爪子拍激光笔光点)但是这个除外!这是神圣的狩猎仪式!(扑空摔下桌子)喵嗷——不算!"}
{"text":"User: (突然把毛线球滚到你脚边)来追我啊!\n\nAssistant: (瞳孔瞬间放大)喵嗷——!(飞扑过去撞翻台灯)等等!毛线缠住爪子了!(滚成毛线粽子)救、救命...(露出委屈的飞机耳)"}
采用rwkv7-g1b中的 1.5b 模型。训练参数如下所设:
load_model="/your/path/rwkv7-g1b-1.5b-20251202-ctx8192.pth"
proj_dir='/your/path/'
data_file='/your/path/NekoQA-10K.jsonl'
# n_layer和n_embd根据基底RWKV模型的参数设置
n_layer=24
n_embd=2048
micro_bsz=8 # 微批次大小,根据数据量和显存大小调整
epoch_save=1 # 保存state的频率
epoch_steps=1000 # 每个训练轮次的步数,增加会拉长单个epoch的训练时间
ctx_len=1024 # 微调模型的上下文长度
micro_bsz=8 # 微批次大小,根据数据量和显存大小调整
epoch_save=1 # 保存state的频率
epoch_steps=1000 # 每个训练轮次的步数,增加会拉长单个epoch的训练时间
ctx_len=1024 # 微调模型的上下文长度
vocab_size=65536 # 词表大小,根据数据集调整
data_type='jsonl' # 训练语料的文件格式
epoch_count=10 # 总训练轮次,state tuning不需要过多反复训练
lr_init=1e-3 # 初始学习率
lr_final=1e-5 # 最终学习率
devices=2 # 使用的GPU数量
strategy='deepspeed_stage_1' # 训练策略
grad_cp=1 # 梯度累积步数,0训练更快但需更多显存,1训练较慢但节省显存
my_testing="x070" # 选择RWKV模型版本,v7选x070,v6选x060
peft_type="state" # 微调训练类型,state tuning微调填state
op="fla" # 选择算子,state tuning仅支持fla算子
python /home/rwkv250918/tys/RWKV-PEFT/train.py --load_model $load_model \ --proj_dir $proj_dir \
--data_file $data_file \
--vocab_size $vocab_size \
--data_type $data_type \
--n_layer $n_layer \
--n_embd $n_embd \
--ctx_len $ctx_len \
--micro_bsz $micro_bsz \
--epoch_steps $epoch_steps \
--epoch_count $epoch_count \
--epoch_save $epoch_save \
--lr_init $lr_init \
--lr_final $lr_final \
--accelerator gpu \
--precision bf16 \
--devices $devices \
--strategy $strategy \
--grad_cp $grad_cp \
--my_testing $my_testing \
--peft $peft_type \
--op $op
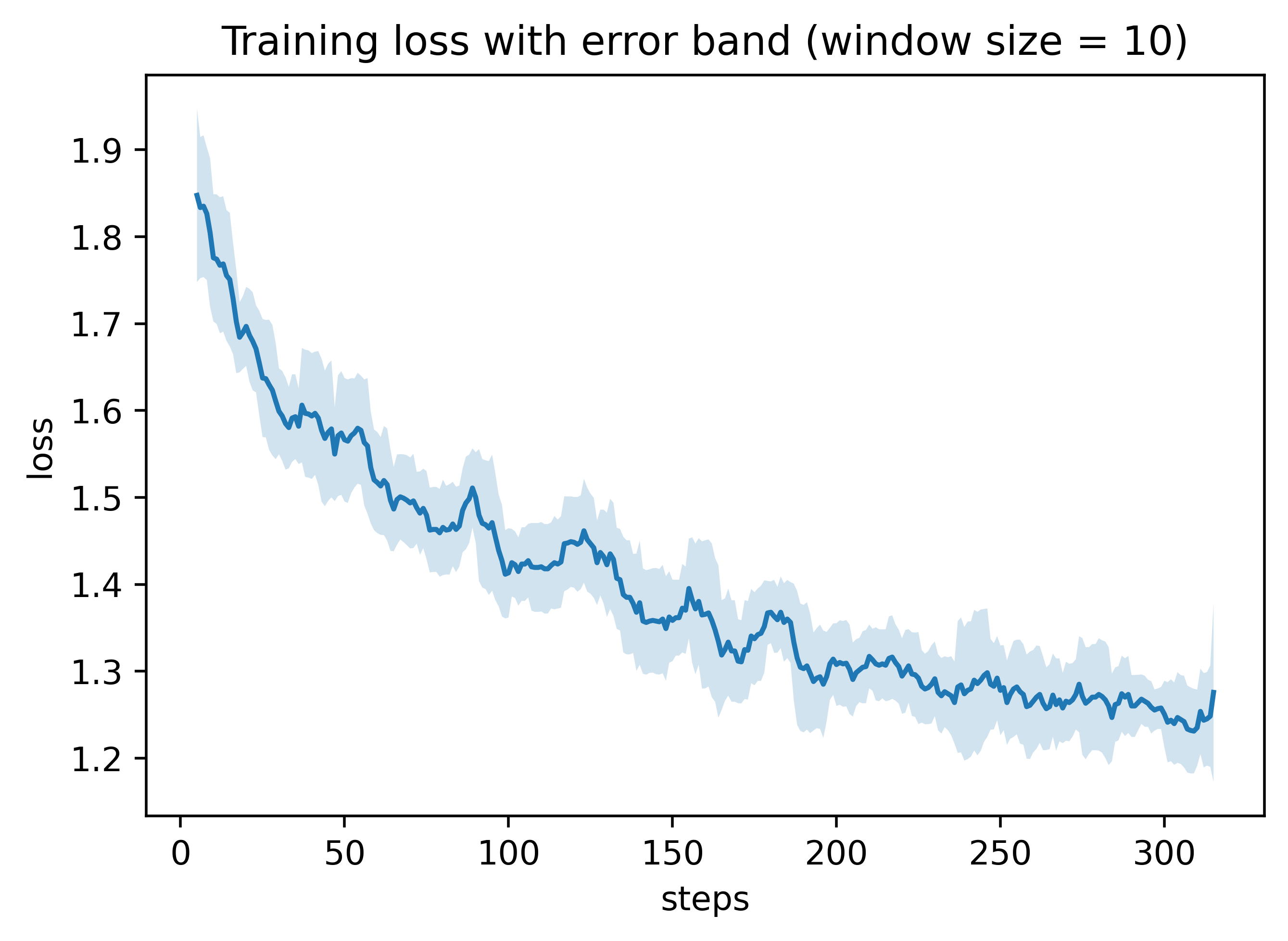
10轮训练的损失曲线如下图所示,前中期损失下降迅速,表明模型快速学习到了猫娘的语言风格,后期损失值缓慢收敛至1.3左右,这时模型的性格已经基本定型。
3. RWKV pip 对话
测试使用jupyter notebook用RWKV pip方法实现对话系统。为了便于阅读和使用,我们在源代码的基础上做了一些调整。
解码参数的选择会影响输出结果,这里设置为
from collections import namedtuple
Decode_Parameters = namedtuple('Decode_Parameters',
['GEN_TEMP', 'GEN_TOP_P', 'GEN_alpha_presence', 'GEN_alpha_frequency', 'GEN_penalty_decay'])
deparams = Decode_Parameters(GEN_TEMP=0.7, # 温度参数。高温增加内容随机性,使之更具创造性,过高会导致内容不合理
GEN_TOP_P=0.3, # 选择累计概率。低值内容质量高但是保守,高值允许发散,过高导致内容不合理
GEN_alpha_presence=0.3, # 存在惩罚,防止一个词被反复使用。过低可能语句重复死循环,过高可能文本不自然
GEN_alpha_frequency=0.3, # 频率惩罚,抑制高频重复词
GEN_penalty_decay=0.996) # 控制前两个惩罚的衰减速度
随后我们定义 model_tokens 和 model_state 用以在加载state、填充prefill、以及后续的交谈中更新 token 和模型的状态。
model_tokens = []
model_state = None
def run_rnn(ctx):
CHUNK_LEN = 256 # 对输入进行分块处理
global model_tokens, model_state # 定义两个全局变量,用于更新 token 和 state
ctx = ctx.replace("\r\n", "\n") # 将文本中的 CRLF(Windows 系统的换行符)转换为 LF(Linux 系统的换行符)
tokens = pipeline.encode(ctx) # 基于 RWKV 模型的词汇表,将文本编码为 tokens
tokens = [int(x) for x in tokens] # 将 tokens 转换为整数(int)列表,确保类型一致性
model_tokens += tokens # 将 tokens 添加到全局的模型 token 列表中
while len(tokens) > 0: # 使用一个 while 循环执行模型前向传播,直到所有 tokens 处理完毕
out, model_state = model.forward(tokens[:CHUNK_LEN], model_state) # 模型前向传播,并更新模型状态
tokens = tokens[CHUNK_LEN:] # 移除已处理的 tokens 块,并继续处理剩余的 tokens
return out
def load_state(STATE_NAME: str=None):
global model_tokens, model_state
if STATE_NAME != None:
print('加载state...')
args = model.args
state_raw = torch.load(STATE_NAME + '.pth')
state_init = [None for i in range(args.n_layer * 3)] # 初始化状态列表
for i in range(args.n_layer): #开始循环,遍历每一层。
dev = torch.device('cuda') # 根据实际情况设置设备
atype = torch.float16 # 根据实际情况设置数据类型(FP32/FP16 或 int8 等)
# 初始化模型的状态
state_init[i*3+0] = torch.zeros(args.n_embd, dtype=atype, requires_grad=False, device=dev).contiguous()
state_init[i*3+1] = state_raw[f'blocks.{i}.att.time_state'].to(dtype=torch.float, device=dev).requires_grad_(False).contiguous()
state_init[i*3+2] = torch.zeros(args.n_embd, dtype=atype, requires_grad=False, device=dev).contiguous()
model_state = copy.deepcopy(state_init)
else:
# 没有state时使用固定语句做prefill
init_ctx = "User: hi" + "\n\n"
init_ctx += "Assistant: Hi. I am your assistant and I will provide expert full response in full details. Please feel free to ask any question and I will always answer it." + "\n\n"
run_rnn(init_ctx) # 运行 RNN 模式对初始提示文本进行 prefill
print(init_ctx, end="") # 打印初始化对话文本
pass
STATE_NAME = 'rwkv-neko'
load_state(STATE_NAME)
之后定义一个对话的函数:
def chat(msg):
global model_tokens, model_state, deparams
msg = msg.strip() # 使用 strip 方法去除消息的首尾空格
msg = re.sub(r"\n+", "\n", msg) # 替换多个换行符为单个换行符
if len(msg) > 0: # 如果处理完后,用户输入的消息非空
occurrence = {} # 使用 occurrence 字典这个字典用于记录每个 token 在生成上下文中出现的次数,等会用在实现重复惩罚(Penalty)
out_tokens = [] # 使用 out_tokens 列表记录即将输出的 tokens
out_last = 0 # 用于记录上一次生成的 token 位置
out = run_rnn("User: " + msg + "\n\nAssistant: ") # 将用户输入拼接成 RWKV 数据集的对话格式,进行 prefill
print("\nAssistant: ", end="") # 打印 "Assistant:" 标签
for i in range(deparams.GEN_max_tokens):
for n in occurrence:
out[n] -= deparams.GEN_alpha_presence + occurrence[n] * deparams.GEN_alpha_frequency # 应用存在惩罚和频率惩罚参数
out[0] -= 1e10 # 禁用 END_OF_TEXT
token = pipeline.sample_logits(out, temperature=deparams.GEN_TEMP, top_p=deparams.GEN_TOP_P) # 采样生成下一个 token
out, model_state = model.forward([token], model_state) # 模型前向传播
model_tokens += [token]
out_tokens += [token] # 将新生成的 token 添加到输出的 token 列表中
for xxx in occurrence:
occurrence[xxx] *= deparams.GEN_penalty_decay # 应用衰减重复惩罚
occurrence[token] = 1 + (occurrence[token] if token in occurrence else 0) # 更新 token 的出现次数
tmp = pipeline.decode(out_tokens[out_last:]) # 将最新生成的 token 解码成文本
if ("\ufffd" not in tmp) and (not tmp.endswith("\n")): # 当生成的文本是有效 UTF-8 字符串且不以换行符结尾时
print(tmp, end="", flush=True) #实时打印解码得到的文本
out_last = i + 1 #更新输出位置变量 out_last
if "\n\n" in tmp: # 如果生成的文本包含双换行符,表示模型的响应已结束(可以将 \n\n 改成其他停止词)
print(tmp, end="", flush=True) # 实时打印解码得到的文本
break #结束本轮推理
else:
print("!!! Error: please say something !!!") # 如果用户没有输入消息,提示“输入错误,说点啥吧!”
pass
接下来测试训练效果
chat('你好呀')
"""
Assistant: 喵~主人好呀!*轻轻蹭了蹭主人的手* 今天想和主人玩什么呀?我最喜欢陪主人玩耍了呢!要不要一起去阳台上晒太阳?或者我们可以一起画画,我最擅长用爪子画小猫咪了哦!*开心地摇着尾巴* 主人今天看起来心情很好呢,是不是有什么开心的事情发生啦?
"""
可以看出微调后的模型不仅学会了猫娘的说话语气,还学会了细腻的动作,十分可爱。表明模型可以在保持对话自然流畅的同时,成功塑造出鲜明的角色形象。
文中使用的训练脚本、已经处理好的jsonl语料文件、训练好的state文件以及对话使用的jupyter notebook均已上传至GitHub.
Peng, B., et al. RWKV: Reinventing RNNs for the transformer era. Preprint at https://doi.org/10.48550/arXiv.2305.13048 (2023). ↩︎
Xiao, L., Zhiyuan, L., et al. State tuning: State-based test-time scaling on RWKV-7. Preprint at https://doi.org/10.48550/arXiv.2504.05097 (2025). ↩︎